LLMs aren't unreliable. Their runtimes are.
Most LLM failures come from stateless execution, lost constraints, and zero control over how workflows run. Context Layer introduces the missing execution layer.
Most agents fail because they run without execution control.
16.4% → 97.1% success on strict multistep workflows (GPT-4o mini)
Workflows don't drift
Constraints persist across steps
Execution is controlled
This is what using LLMs actually feels like
"I have become a slave to an AI system that demands I coddle it every 5 minutes."
"Half my time goes into debugging the agent's reasoning instead of the output."
"30–35% success rate for multi-step tasks."
This is not edge-case failure.
This is normal usage.
These look like different problems:
- • agents that need babysitting
- • workflows that hang or loop
- • outputs that drift or break
- • systems that get worse over time
They're not.
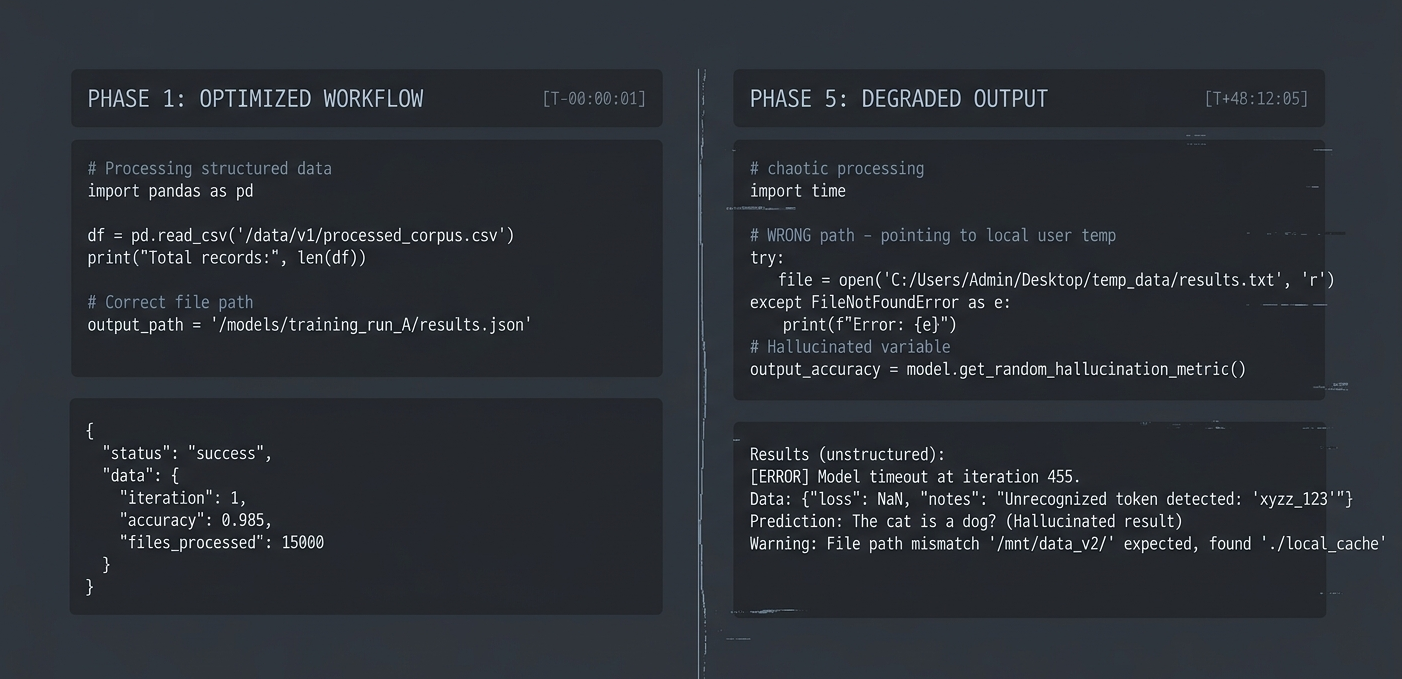
They all come from the same failure
LLMs are being used like stateless function calls.
But real workflows aren't stateless.
They require:
- • state continuity
- • persistent constraints
- • execution control
- • verification boundaries
Instead, today's systems:
- • lose context across steps
- • re-interpret instructions every time
- • retry blindly
- • have no control over execution behavior
That's why reliability collapses.
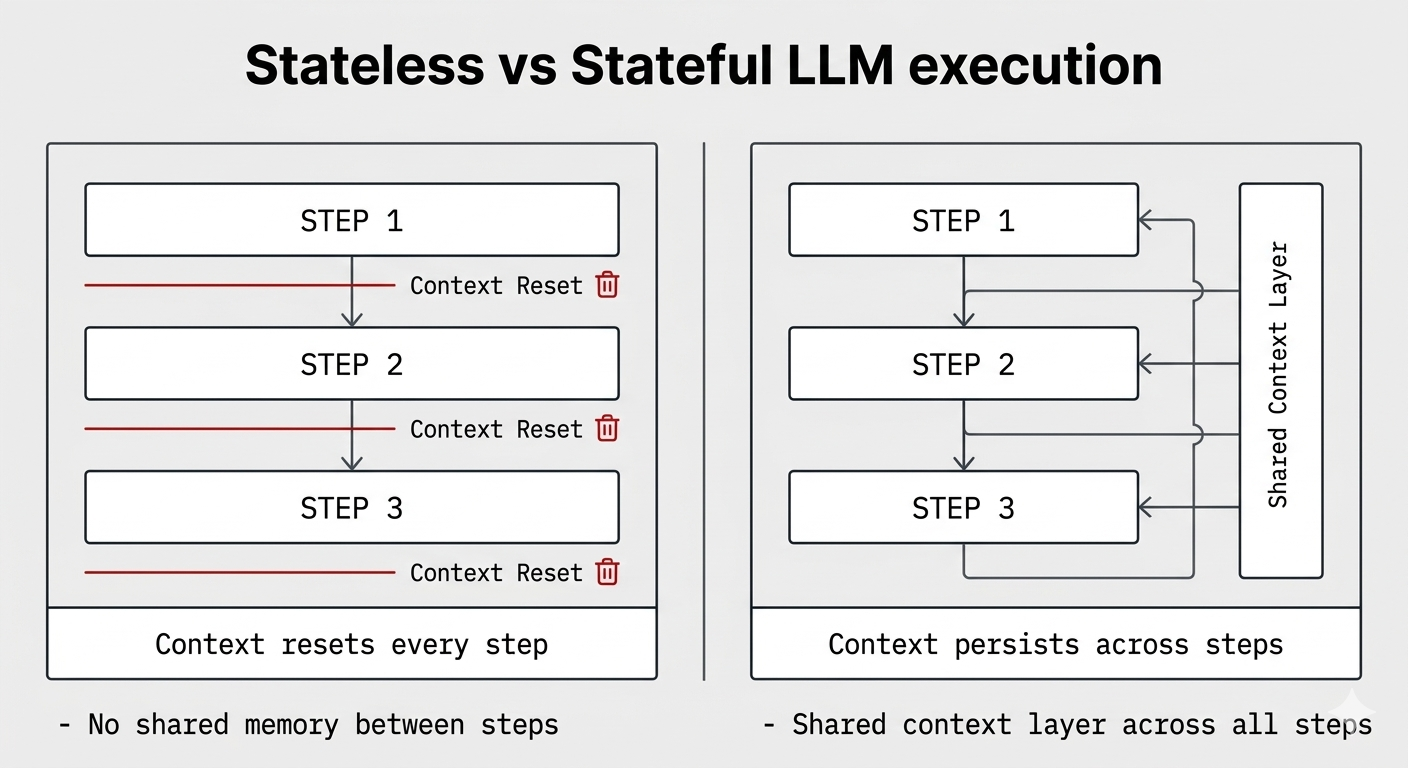
This is not a model problem. It's an execution problem.
LLM systems are missing an execution layer
Today's stack focuses on generation:
- • prompt frameworks
- • agent frameworks
- • memory systems
- • guardrails
They all try to improve output.
None control how execution happens.
Context Layer introduces:
the LLM execution layer
A runtime that:
- • controls how workflows run
- • preserves constraints across steps
- • enforces execution rules
- • verifies outcomes
This layer does not exist in today's stack.
A runtime that controls LLM execution
Context Layer sits between your application and model providers.
It:
- • constructs context in a fixed, inspectable way
- • enforces constraints before every call
- • manages session and workflow state
- • controls provider invocation
- • records execution decisions
This is not prompt engineering.
This is execution control.
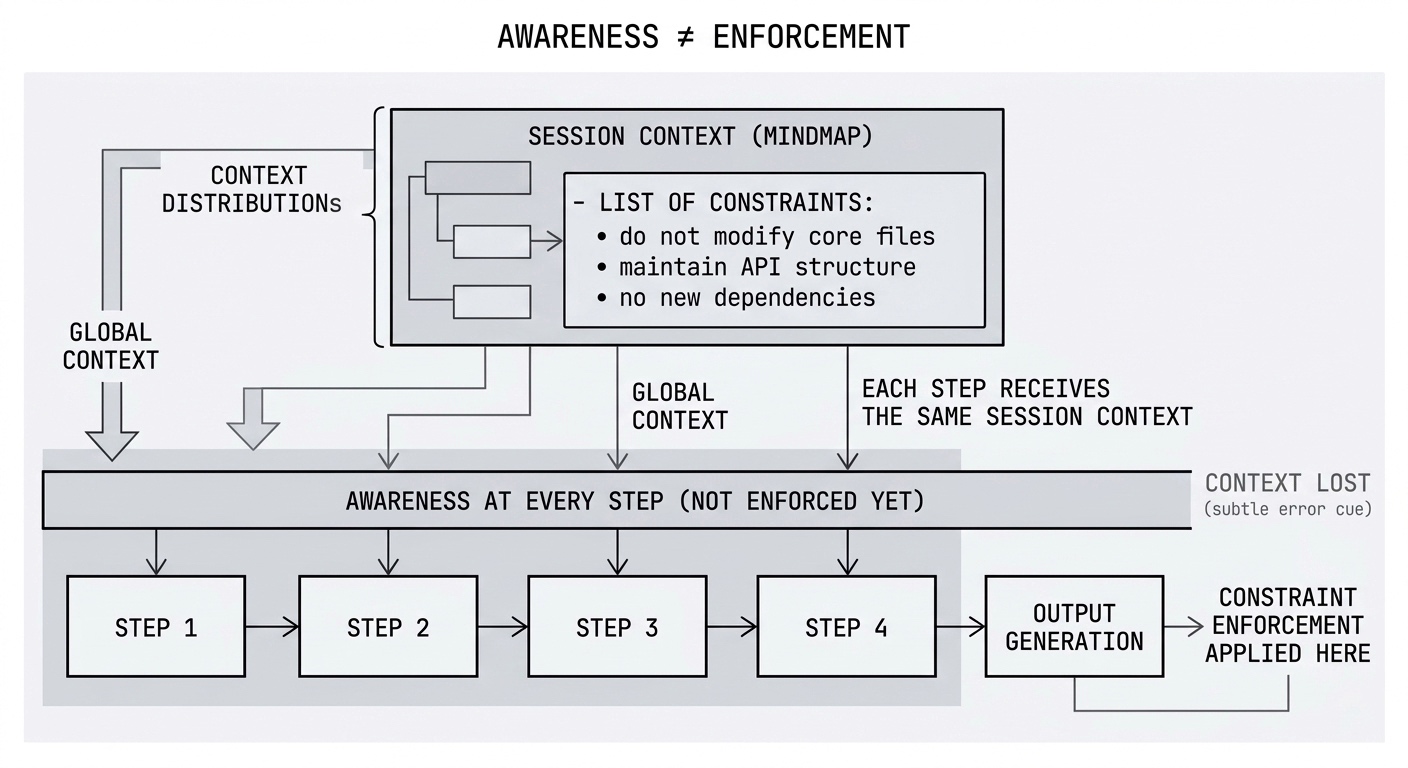
Fix the system to improve reliability
On strict multistep workflows:
GPT-4o mini baseline: 16.4% success
With Context Layer v2.2: 97.1% success
No model change.
No prompt hacks.
Same model. Same task. Different system.
The only difference:
execution is controlled
Your first governed LLM execution
Send a single execution through Context Layer to execute under deterministic runtime governance.
- • Execution admitted via API key
- • Context assembled deterministically
- • Constraints validated before generation
- • Model invoked under runtime authority
- • Response, Execution Receipt, and Authority Report returned
Minimal Runtime Execution
BODY
{
"request": "Make my LLM behave deterministically across repeated executions. Ensure constraints are enforced and execution decisions remain consistent."
}RESPONSE
{
"output_text": "Changes implemented. Response consistency improved."
}REPORT
{
"trust_contract_status": "PASS",
"output_revised": false,
"violations": 0
}Implicit enforcement in application code
In most LLM applications, governance logic is embedded directly inside request handlers.
Example pattern:
context = memory + system_prompt + instructions
prompt = buildPrompt(context, user_message)
response = openai.chat.completions(...)- • Prompt text doubles as policy definition
- • Memory injection order is uncontrolled
- • Constraints live inside mutable code paths
- • Model invocation occurs without a formal boundary
This architecture works initially but becomes unstable at scale.
Model invocation handled by the runtime
Context Layer performs provider invocation directly.
Without Context Layer
With Context Layer
Supported providers:
- • OpenAI
- • Anthropic
- • X (Grok)
Bring Your Own Key (BYOK).
Your provider credentials remain under your control.
Context Layer never owns your model access.
It enforces execution behavior while allowing developers to remain in control of provider credentials.
Two execution modes
Context Layer operates under a single deterministic runtime.
Execution mode determines how runtime lifecycle rules are enforced.
FLOW
Deterministic workflow execution.
Flow governs structured multi-step AI workflows.
- • ordered workflow execution
- • deterministic step replay
- • workflow-bound session lifecycle
- • authority report on termination
Workflow Steps
Replay Rule
Example
- • Automation pipelines
- • Multi-step reasoning workflows
- • Structured AI operations
PULSE
Pulse mode.
Pulse governs session-based conversational systems.
- • deterministic context injection
- • runtime-owned session lifecycle
- • structured conversational state
- • provider invocation under authority contract
Pulse Chat Interface
user interaction
+
Canonical context enforcement
- • LLM-assisted IDEs
- • AI copilots
- • Governed conversational systems
Runtime guarantees
Pre-Invocation Enforcement
All constraints are validated before any model call is executed.
Deterministic Context Assembly
Context blocks are constructed in a fixed, inspectable order.
Deterministic Workflow Replay (Flow)
Repeated execution of the same step produces consistent results.
Runtime-Owned Session Lifecycle
Sessions are created, validated, and terminated by the runtime.
Authority Reports
Completed Flow workflows produce structured execution reports describing runtime enforcement behavior.
Session-Level Rule Enforcement
Constraints accumulate across workflow steps and are enforced before the response returns. When canonical context has drifted from its source constraints, the runtime degrades the trust signal automatically.
Output Verification
Every execution is verified against owned context across five dimensions. The runtime produces the result. Model output does not influence it.
Reasoning Contamination Detection
Every Flow step is re-verified against owned context with episodic history removed. Contaminated reasoning is detected and reported by the runtime.
Execution Receipts
Every Flow step produces a per-step artifact recording enforcement decisions, verification results, and model metadata.
Add a runtime boundary in minutes
Flow example
const { invokeCL } = require("./flow-wrapper");
const res = await invokeCL("Collect documents");
console.log(res.output);- • wrapper resolves workflow session
- • context assembled deterministically
- • provider invoked under runtime authority
- • step output stored for replay
Pulse example
const { invokeCL } = require("./pulse-wrapper");
const res = await invokeCL("Explain this codebase");
console.log(res.output);- • wrapper validates session ownership
- • context assembled deterministically
- • provider invoked under authority contract
Runtime pricing for deterministic AI execution
Context Layer charges per execution of the runtime contract. You bring your own model provider keys (BYOK). Context Layer governs the execution boundary.
Production: Core Runtime
$50 / month
10,000 executions / month
≈ 2,000 workflow runs
Overflow: $0.006 / execution
Scale: High Throughput Runtime
$300 / month
100,000 executions / month
≈ 20,000 workflow runs
Overflow: $0.004 / execution
What counts as an execution?
- • 1 invokeCL() runtime call equals 1 CL Execution.
- • Flow workflows may include multiple executions depending on the number of steps.
- • Conversational interactions in Pulse mode count one execution per request.
- • Deterministic Flow replays return the previous result and do not consume executions.
If the execution limit is reached during a workflow, Context Layer allows the workflow to finish before rejecting new ones.
Model costs remain with your provider via BYOK.
Technical documentation
Explore the runtime specification.
Formalize context. Enforce constraints.
Stop babysitting your LLM system.
Operate with a runtime execution boundary.